Ubie株式会社(Ubie Discovery)に入社しました
4月からUbie株式会社で働き始めました。 入社して1ヶ月が立ったので, 入社に至るまでの経緯と入っての感想を簡単にまとめようと思います。
こういう記事でエモい内容書くの苦手だし, 自分が長い文章読むのも苦手なので, 簡潔めにまとめています。 気になった部分あった方はぜひ直接お話しましょう! (TwitterDMなどで気軽に連絡いただければ @Schumi543)
Ubieの選考に進んだきっかけ
- 2年ほど前に参加した勉強会で @nantani4 さんと知り合った、その後youtrustで声がけいただいて, カジュ面で何人か話を伺っていた
- もともとブログを見ていた, @shiraj_i さんや @yohei_kikuta さんが転職してたのをtwitter で見かけて気になっていた
- podcast 聞いて, 一緒に働いて楽しそうな人が多そうだと思っていた
- カルチャーガイド や noteの発信 見てユニークな組織設計をしているなと思って興味が湧いた
Ubieに決めた理由
他にはスタートアップといわゆる大手外資系企業を数社受けて内定をいただいていました。 最終的にUbieに決めたのは以下の理由です。
- 選考でのやり取りやメンバーの普段の発信(note, podcast)を見て一緒にはたらいて楽しそうな人が多いと思った
- 自分の価値観とマッチした
- 価値観は詳細に書くと長くなるので端的に書くと, 人がやりたいことできている(少なくともやりたくないことをやらなくてよい)社会つくりたいなと思っています。
- 実際にプロダクトや事業の話を聞いて, 自分の身の回りの人の生活をよくできそうなものが作れそうだと感じた
- 待遇が十分良かった
- ビジネスロジック的なところを聞いておもしろそうだと感じた
- 大手外資系企業はJrの立場で行ける年齢的には最後そうかなーと思いつつ, ライフステージ的なところも考えて, 今しかできない経験ができるのはUbieの方だなと思った。
実際に働いての感想
入社前の懸念と実際
懸念についてはだいたい面接時点で聞けてたのでそこまでなかったんですが, 以下の点だけ気にしていました。
実際働いてみた感想としては以下の対策がされていたので, 全く問題なさそうでした
- 実際は前職が少なすぎただけでそこまでmtg多くはなさそう
- 会議体のあり方も教条的にやるのではなくscrumの原則に従って適応的に更新されている
- 加えて, ホラクラシーのロールで
生産性最大化に向けた社内Mtg最適化というのもあって, 全社員のmtg時間モニタリングして適宜振り返ってアクションをうっている - notionに
ホラクラシーの会議が溢れることを恐れているあなたへという記事があって, まさしく参考になる情報があった
また, 実際に入って気づいたこととしては, DX(Digital Transformation)をやっているという会社ということでPublic Affairs(公共政策渉外)をやっている人がいるのは, 今まで見てきたApp, Web系の企業ではあまり見かけてこなかったので, 新鮮でした
カルチャー
想像していた以上に カルチャーガイド の通りでした。 特に普段の業務で感じる部分は以下です。
- 当たり前のレベルが高く, 投資対効果(RoI)あうなら, 方法論にはこだわらずやりきる
- 諸々の効率化のためののレールとしての決まりはあるが, 目的に適さなかったらすぐ変えていく
- カルチャーガイドのUbienessやDo's, Don'ts が徹底されている印象
各所にカルチャーについて振り返る機構があるのでポジティブフィードバックが起こりやすい note.com
コミュニケーションの共通規格として, UbienessとDo's, Don'ts 浸透しているので, 人で話し方を変えるというのが少なくてやりやすい
- 少し意外だったところでいうと, ドメインが医療DXということで, 少し硬めの人が多いかなという印象だったが, いい意味で真面目さと普段のラフさのgapが大きい人が多い
オンボーディング
- 以前のnote記事にあったようにオンボーディングはかなりしっかりしていました。
- 3日間に渡って, 会社のカルチャー, ドメイン, チームなどに関してみっちり教わった
- 3-2-1リストという, 入社3日以内, 2週間以内, 1ヶ月以内にやることリストがまとまっていたので, 事務的な作業のチェックがしやすかった
- 初日オンボーディングで個人OKRを立てたのが, 休み明けで仕事の仕方忘れてたのを切り替えるのに良かった
- 最後にアンケートでオンボーディングのフィードバックや
能力発揮度,心理的安全性,Value発揮度について回答, 答えた内容についてメンターと話し合いました。自分の今の立ち位置が整理されてよかった
この1ヶ月でやっていた業務
一旦DSの直近のOKRに基盤改善系のPBIがつまれていたので, その辺りを扱っていました。
- オンボーディングタスクとしてドキュメントやツールのアップデート
- A/Bテスト基盤の開発
- 開発効率改善のためのissue作成
- 検証用のシミュレータの整理
- ロジックの検証
- 採用
ポジション的にはデータエンジニアで入ったのですが, 前職でもロジックの改善と基盤改善両方やっていたので, その辺りを両方やっている感じです。 いわゆる検証, 開発, 運用のプロセスをすべて扱えるのはこの職種の面白いところだな〜と思っています。
まとめ
発信されている情報といい意味でギャップが少なくて, とても働きやすい環境です。
自分が所属するData Science Teamはメンバー増えてきたんですが, メンバーがみんな自分でissueを見つけてくるタイプの人というのもあって, やりたいことがすごい勢いで増えていくので絶賛採用中です。
Ubieに興味ある人はぜひ一度話しましょう, その他キャリア的なことや最近のData Science/Engineer系の仕事の個人的な雑談とかも受け付けてます。
冒頭に書いたTwitterDM or 以下のフォームからカジュアル面談からぜひご連絡ください。
統計数理研究所 オープンハウス 基調講演メモ
統計数理研究所75周年のオープンハウスに参加してきたので手元のメモ公開します。
イベントHP www.ism.ac.jp
人工知能の歴史, 発展, 社会への影響(甘利先生)
前半は一般の方向けのライトな話でした。 メモは若干自分の解釈が入ってます。
イントロ
第四時産業革命
生命技術と方法技術の進化 技術は止めようと思っても止まらない
宇宙史と脳の生成のアナロジー
物理学 (ビッグバン)->生命科学 (生命の誕生, 事故を複製し次世代に伝える物質, 遺伝)->神経科学 (多細胞生物は環境情報を利用する)->文化人類学, 心理学 (人類の誕生と発展)
人工知能と脳のモデル
AIの第一次ブーム
万能機械, Perceptron, 脳モデル
神経回路ネットワークモデル(ローゼンブラッド) 計算機の性能が足りなかった
AIの第二次ブーム
エキスパートモデル, MLP(backprop), 連想記憶モデル
AIの第三次ブーム
深層学習の数理(digest)
多層回路網の学習理論は甘利先生が約50年前に提案
深層学習の問題点
1. 原理を発見しない -> モデルの数理的解釈が難しい
理想のモデルの設計, 潜在変数の特定までは難しい, 例えばケプラーの法則を発見できるか?
モデル選択の話?
2. 1000 層も必要か?
layor 数の暴力で問題を説いている, 情報表現としては抽象化が進めば構造が捉えられる 敵対的例題と脆弱性
3. 局所解と大域解
次元の呪いと局所解 simulated annealingで何とかしようという話はあるが, approachが工学的... 大規模系の特徴 n->∞ での関数空間での評価 Jacot et.al
最近の甘利先生の研究
統計神経力学
例えばinitial weightを適当な確率分布で初期化したときにマクロな何らかの数理的な特徴が捉えられないか
Stanford, Google の人たちも最近やり始めている
引き戻し計量(リーマン計量, 距離)
フラクタルと敵対的例題 Poole et al. 2016 (甘利先生がやりたかったらしい)
中心極限定理, 大数の法則を使いたいが, 層には方向があるので一様収束しない
Natural Gradient 計算機的に逆行列計算が現実的でない(1M * 1M parameters)
Fisher Information, Unitwise natural gradient Y.Ollivier
quasi-diagonal nartural gradient
neural tangent kernel (No local minima, uniform convergence) $n -> \inf K_t -> K_0$
数理脳科学は脳の基本原理を探求する
進化によるランダムサーチ
GA, MCMC?
歴史的な制約, ゴタゴタの設計の中で絶妙な実現
意識の発生
Libetの実験 予測と後付, 神経科学的ダイナミクス <=> 意識による反省, 正当化
人工知能が脳に学ぶべきこと
数理的理解, 意識と心の役割, 連想式記憶システム
心を持ったロボットがつくれるか
ロボットが心を持つように見える(感情移入)
社会への影響
人間の家畜化, ベーシックインカム 仕事がないと人は生きられない, Amateur Scientist, Enginnerが増えていく?
深層生成モデルによる統計的推論(福水先生)
最近の深層生成モデルによる統計的推論のsurvey的な話
イントロ
神経回路網の数理がきっかけで統計的機械学習に興味を持った NN -> SVM -> DNN
DNNの発展にはプラットフォームの起用もある(RF, PyTorch Theano, Chainer)
"Artifucuak Intelligence is the new electricity" by Andrew Ng
深層生成モデル
GAN-> ProgressiveGAN->StyleGAN
StyleGAN (which face is real?)
良い原理が発見できれば, 改善は速い
現在のSoAとして以下を紹介 CycleGAN(2017) Everybody Dance Now (2018)
数理的な話
生成モデル自体は昔からある i.e. Graphical model, Mixture model, カーネル密度推定
距離尺度 i.w. f-divergence(2016), wasserstein(2017), MMD(2018) GANはJensen-Shannon divergenceを利用, 確率密度関数の構成が困難-> JS距離を識別問題に還元-> 識別はDNNが得意
GANはminimaxによる学習, DiscriminatorはLogistic Classify, Genrator は判別できないようにモデルを生成
深層生成モデルによるベイズ推論
ベイズ問題の一つは分母の積分をどう計算するか GANは高性能なサンプラーと考えられる, ベイズ推論に使えないか? Yang et.al. 2018
分布の距離尺度は KL-d, 変分ベイズからの導出 Hierarchical Impicit Models and Likelihood-Free VI
密度比の対数の推定をLogictic Classify で行う(like GAN) 実験の比較対象はABC系の手法 Lotca-Volterra Predator-Prey Simulator の推論
おわりに
今後の研究対象は以下
- GANによるサンプリング+Bayes推論
- 非線形時系列モデル
GANによるサンプリングを利用した粒子フィルターおもしろそう
深層学習の理論を明らかにする理論の試み(今泉先生)
イントロ
深層学習の登場 膨大な計算コストとブラックボックスな挙動が未だに実用化の課題
深層学習のモデルに関するイントロ
AlexNet #layer = 8, #parameter=60M VGG #layer =19, #parameter =100M
深層学習がもたらす謎
- なぜ性能が良いのか?
従来法: フーリエ法, スプライン, カーネル法 これらは大雑把には特徴写像-> 線形変換の二層の構造と考えられる
一方でDNNは #layerが多いので表現力が高い(?)
謎1. なぜ多層で性能が上がる
関数推定の最適性原理, 普遍近似原理 .. etc. があるにもかかわらず #layerと性能は正の相関がある
謎2. パラメタ数の謎
統計理論の原則としては, 大量のパラメータを持つモデルは過学習により精度が下がるはず, but DNNはパラメータ数と性能に正の相関がある 既存手法は変数選択, スパースモデリング, 正則化, 適応化などでモデルのパラメータ数を減らす方向でモデリングしてきた
謎3. なぜ学習が収束する?
次元の呪いがあるはずなのに, 適当なパラメータで精度が向上している(従来の統計理論とConflict) パラメータは大域解でないのに信頼できるか?
原因究明のための理論の試み
1. 多層構造が必要な関数
斉一的な性質を持つ関数 -> 局所構造を持つ関数
多層は局所構造を持つ関数の表現に必要 i.e. 相転移現象の特異関数(Imaizumi 2019), 信号, 音声のBesov 関数空間(Suzuki 2019)
supportが分離されているような局所構造のある関数を保表現するにはDNNの多層構造が有用なことが理論的に示された
2. モデル自由度の再評価
既存の解釈ではモデル自由度=パラメータ数, か適合しやすい(VC次元, R複雑正) 深層学習の経験値によるとパラメータ数が増えてもモデルの自由度は低い 自由度 = f(パラメータ) の f' >0 ∧ f" < 0では?とう言う話
実際の自由度を何で決めるかという点について, 近年研究されている Bartlett(2017), Arora(2018)
多様な自由度の尺度が提案されているが, 汎用的・統一的な理論は今後の課題
3. 大域解を保証する仕組み
Over-Parameterization 損失が押し下げられるため, 大域解への到達が容易になる(?) Allen-Zhu(2019), Liang(2018), Kawaguchi(2019)
Over-Parameterization に必要なパラメタ数は データ数Dに対して O(D30)
解決への一つの方針が発見されたが, 詳細は非現実的で研究が必要
おわりに
統計理論は何をするべき? 昔は理論的な保証を与えたが, 現在は計算機が保証を作れる
理論側は現象から問題を輸入, 既存理論を再構築していく必要がある そのうえで現象に知見を提供, 計算機科学, 物理学との理論的貢献の競争
発見を理論で体系化する, 体系化されない知見は忘却されやすい
読書メモ Defining Productivity in Software Engineering
Splinger link でCCライセンス で公開されていた Rethinking Productivity in Software Engineering | SpringerLink が面白そうだったので, Chap. 4 "Defining Productivity in Software Engineering" を読んだメモを公開する。 自分の解釈が入ったメモなので正確に内容を追いたい方は原文を参照されたし。
Introduction
- 部門によらず生産性の定義は output/inputとして考えられる
- input に関してはソフトウェアの文脈では比較定義が簡単。
- (human resource, computation resource にかかる資本投下?)
- output の定義が難しく一般的には数量, 品質が定義になるがこれらを普遍的に測定する方法を定義するのが難しい
- そのうえoutputに影響を与えうる 要因の分析, 測定, 比較などに有効な方法やツールが明確に定義されていない
- 本文献では ソフトウェア開発における生産性改善のために, 関連する用語(効率性、有効性、パフォーマンス、および収益性) の定義の確認とそれらの関連性について説明する。
用語の定義
生産性(Productibity)
Introで述べられたように分野によらず, 普遍的に定義されるもの
Productivity = Output / Input
古典的な製造業においては, (単位時間当たりに生産される単位数)/(生産で消費される単位数) で直接的に表現できるが, 作家, 科学者, SWEなどのナレッジワークではアウトプットに品質、適時性、自律性、プロジェクトの成功、顧客満足度 など複数の考慮すべき要素があるため未だ普遍的な定義は存在しない。
収益性(Profitability)
収益性と生産性はしばし混同される。収益性は生産性の Input を得るためのCost, Output を取引することで得るProfitまで考える。
Profitability = Profit / Cost
従って生産性は変わらずとも物価の上昇や, 資源価格の変動など外部条件によって収益性は変動しうる。 収益性の変動要因は生産性より多い。
パフォーマンス(Performance)
パフォーマンスは収益性より更に広範な企業の成功に影響を与える要因を含む指標。 顧客の認識度, 満足度などを含む。
効率性と有効性(Efficiency and Effectiveness)
しばし, 混同されるが, 効率と有効性は別の概念であり, 効率はinput に作用するもの, 有効性はoutputに作用するもの として本文中では定義されている。 以下の図がわかりやすい。
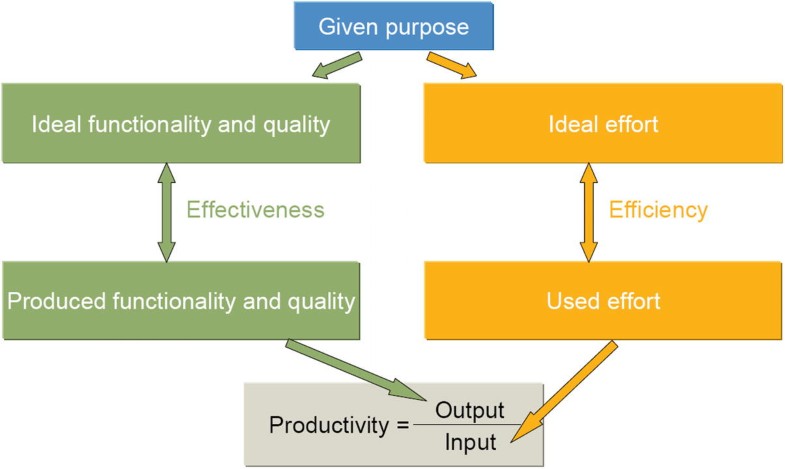
品質(Influence of Quality)
生産性の項で述べたように, ナレッジワーカーの生産性を定義する要素として存在するもの。 いくつかの文献で定義を行おうと試みられているものの未だ生産性との関連性を運用可能な概念として明確に定義したものは存在しない。
PEモデル
前節で定義した用語に対して, Tangen の triple-P-model の拡張モデルとして本文献では以下のPEモデルが提案されている。 PEモデルによって前節で定義したモデルのすべての用語の関連付けができる。
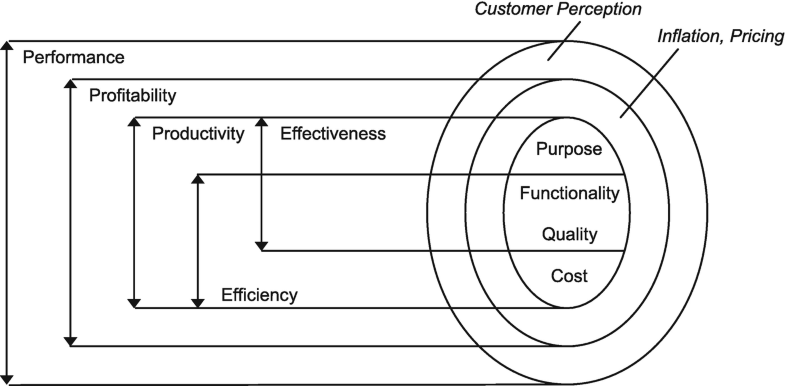
追加された要素は以下
- 収益性とパフォーマンスを関連付けるものとして, 顧客の認識度を追加
- 生産性と収益性を関連付けるものとして, インフレーションと価格設定を追加
- 有効性と効率性の位置づけを追加
感想
- 抽象的な話が多くて理解しにくかったが, PEモデルの図自体は納得いくものだった
- Quality とFunctionality の境界が曖昧なのは納得, 機能要件と非機能要件の線引は難しい
- short paper なのもあって関連研究も見ないとイマイチピンとこない。 Customer Perception はマーケティング文脈の話だと思われるが, PEモデルの分割において対称性がうまく反映できていないように思った。
プログラミング言語 Zigについて簡単に調べた
最近, Quoraで尊敬するエンジニアの方々の回答を眺めるのが趣味なのだが, 回答で少し気になったものがあった。
これから間違いなく需要があるプログラミング言語はどれになりますか? - Quora
こちらのMatzの回答で, 「未来に需要が高まると良いな」と思っている言語として Julia, Crystal, V, Zig があげられている。 Juliaは研究で使っていた, Crystalは趣味で少し書いた, VはTwitterで見かけたので知っていたがZigは聞いたことないなと思ったので少し調べてみた。
ググったり, qiita検索しても日本語の記事は見当たらなかったので, まだマイナーな模様。 はてぶで何人か言及しているくらい。 http://b.hatena.ne.jp/entry/ziglang.org/
対抗言語は 同じく Cのreplace狙っている C++, Rust, Dあたりぽい。
公式ドキュメントのFeature Highlight から特に気になったものを抜粋する. https://ziglang.org (調べただけで実際に動かしてはないので勘違いがあるかも)
Small, simple language
プログラミング知識のデバッグではなく, アプリケーションのデバッグに集中するための言語 とある。 実際文法の仕様も500行に収まっている模様。 https://ziglang.org/documentation/master/#Grammar
また, C++, D, Rust の以下のような 隠された制御フローを持たない
- operator overloading
- throw, catch による異なるmethod呼び出し
Performance and Safety: Choose Two
パフォーマンスと安全性を両立している
パフォーマンスに関して, Cより高速 (すごい)
理由は以下らしいが低レイヤの知識が怪しくて詳細は理解できていない...
- LLVM backendを利用
- C compiler にはできない未定義動作の許容による, パフォーマンスチューニングが可能
- link time optimizationの自動化
また, 安全性の観点からは overflowなどはbulid optionを付けることでコンパイル時に詳細に検出することが可能になっている。
test "integer overflow at runtime" {
var x: u8 = 255;
x += 1;
}
$ zig test test.zig
1/1 test "integer overflow at runtime"...integer overflow
/home/andy/dev/www.ziglang.org/docgen_tmp/test.zig:3:7: 0x2040f0 in test "integer overflow at runtime" (test)
x += 1;
^
/home/andy/dev/zig/build/lib/zig/std/special/test_runner.zig:13:25: 0x22752a in std.special.main (test)
if (test_fn.func()) |_| {
^
/home/andy/dev/zig/build/lib/zig/std/special/bootstrap.zig:126:22: 0x226cb5 in std.special.posixCallMainAndExit (test)
root.main() catch |err| {
^
/home/andy/dev/zig/build/lib/zig/std/special/bootstrap.zig:47:5: 0x226a20 in std.special._start (test)
@noInlineCall(posixCallMainAndExit);
^
Tests failed. Use the following command to reproduce the failure:
/home/andy/dev/www.ziglang.org/docgen_tmp/test
パフォーマンスのボトルネックになりそうなら未定義動作を許容することも可能
test "actually undefined behavior" {
@setRuntimeSafety(false);
var x: u8 = 255;
x += 1; // XXX undefined behavior!
}
A fresh take on error handling
try catch による例外処理を持っている, errorが起きないというケースのassert をunreachableで行うというのは他の言語ではあまり見ない仕様かもしれない。
unreachable.zig
const std = @import("std");
const File = std.os.File;
pub fn main() void {
const file = File.openRead("does_not_exist/foo.txt") catch unreachable;
file.write("all your codebase are belong to us\n") catch unreachable;
}
$ zig build-exe unreachable.zig
$ ./unreachable
attempt to unwrap error: FileNotFound
/home/andy/dev/zig/build/lib/zig/std/os.zig:530:33: 0x206411 in std.os.posixOpenC (unreachable)
posix.ENOENT => return PosixOpenError.FileNotFound,
^
/home/andy/dev/zig/build/lib/zig/std/os/file.zig:37:24: 0x2061c7 in std.os.file.File.openReadC (unreachable)
const fd = try os.posixOpenC(path, flags, 0);
^
/home/andy/dev/zig/build/lib/zig/std/os/file.zig:50:13: 0x21c8e3 in std.os.file.File.openRead (unreachable)
return openReadC(&path_c);
^
???:?:?: 0x2272a7 in ??? (???)
/home/andy/dev/www.ziglang.org/docgen_tmp/unreachable.zig:5:58: 0x2271d5 in main (unreachable)
const file = File.openRead("does_not_exist/foo.txt") catch unreachable;
^
/home/andy/dev/zig/build/lib/zig/std/special/bootstrap.zig:116:22: 0x226bda in std.special.posixCallMainAndExit (unreachable)
root.main();
^
/home/andy/dev/zig/build/lib/zig/std/special/bootstrap.zig:47:5: 0x2269d0 in std.special._start (unreachable)
@noInlineCall(posixCallMainAndExit);
^
Generic data structures and functions
多言語にもよくある型変数とジェネリクスによるシンプルなデータ構造の定義が可能
test.zig
const std = @import("std");
const assert = std.debug.assert;
test "types are values" {
const T1 = u8;
const T2 = bool;
assert(T1 != T2);
const x: T2 = true;
assert(x);
}
$ zig test test.zig 1/1 test "types are values"...OK All tests passed.
generics.zig
const std = @import("std");
fn List(comptime T: type) type {
return struct {
items: []T,
len: usize,
};
}
pub fn main() void {
var buffer: [10]i32 = undefined;
var list = List(i32){
.items = &buffer,
.len = 0,
};
std.debug.warn("{}\n", list.items.len);
}
$ zig build-exe generics.zig $ ./generics 10
おわりに
プログラミング言語 Zigについて, 公式ドキュメントを参照して主な機能について簡単に紹介した。
今回紹介した機能以外にも https://ziglang.org/#Feature-Highlights に主要な機能がまとまっているので, 気になった人はぜひ読んでみて(あわよくば解説記事を書いて)ほしい。
rust にやりたいと思いつつ, 所有権で挫折していたので, Zigもドキュメント読みながら軽く触ってみる予定。
zplug -> zplugin に乗り換えた話 (+ exit code のbug調査)
TL;DR;
- plugin managerを zplugから zplugin に乗り換えた. 結果, 起動時間は1/2 ~ 1/3 程度になった.
- zpluginの簡単な紹介
setopt print_exit_valueはzshの設定ファイルから外さないとバグる
※ドキュメントはまだそこまできちんと読んでないので, 記述に間違いがあるかも
はじめに
少し前にzshの起動が遅いのが気になってプロファイル取ったら plugin のloadで時間くってることが判明したため, plugin managerを zplugから zplugin に乗り換えた.
zpluginとは?
Zdharma Initiative のプロジェクトの一つで zplug などと同様のplugin manager
特徴として, 透過的かつ自動的に pluginをコンパイルしてくれる + 遅延読み込みの記述が容易 なため, zsh の起動が他plugin と比べて著しく速い.
意外とまだzsh のplugin managerの中ではマイナー な模様. google のsearch trendだとこんな感じだった.
- world-wide
- Japan
Qiitaだとzpluginの記事は7件ほど https://qiita.com/search?q=zplugin
どれだけ早くなったか
論より証拠で time benchmarkの結果を示す, およそ起動は 1/2 ~1/3 になった印象.
zplug
~
❯ for i in {1..10}; do time ( zsh -i -c exit ); done
( zsh -i -c exit; ) 0.36s user 0.44s system 52% cpu 1.530 total
( zsh -i -c exit; ) 0.39s user 0.44s system 65% cpu 1.258 total
( zsh -i -c exit; ) 0.37s user 0.41s system 65% cpu 1.197 total
( zsh -i -c exit; ) 0.36s user 0.40s system 65% cpu 1.170 total
( zsh -i -c exit; ) 0.37s user 0.42s system 66% cpu 1.197 total
( zsh -i -c exit; ) 0.38s user 0.41s system 65% cpu 1.198 total
( zsh -i -c exit; ) 0.36s user 0.39s system 65% cpu 1.142 total
( zsh -i -c exit; ) 0.37s user 0.40s system 64% cpu 1.194 total
( zsh -i -c exit; ) 0.35s user 0.39s system 63% cpu 1.163 total
( zsh -i -c exit; ) 0.31s user 0.33s system 64% cpu 0.992 total
zplugin
~
❯ for i in {1..10}; do time ( zsh -i -c exit ); done
( zsh -i -c exit; ) 0.17s user 0.19s system 69% cpu 0.513 total
( zsh -i -c exit; ) 0.18s user 0.20s system 72% cpu 0.527 total
( zsh -i -c exit; ) 0.17s user 0.18s system 73% cpu 0.464 total
( zsh -i -c exit; ) 0.17s user 0.19s system 72% cpu 0.489 total
( zsh -i -c exit; ) 0.17s user 0.18s system 72% cpu 0.468 total
( zsh -i -c exit; ) 0.17s user 0.19s system 71% cpu 0.509 total
( zsh -i -c exit; ) 0.17s user 0.19s system 71% cpu 0.506 total
( zsh -i -c exit; ) 0.17s user 0.18s system 73% cpu 0.477 total
( zsh -i -c exit; ) 0.16s user 0.18s system 74% cpu 0.460 total
( zsh -i -c exit; ) 0.17s user 0.18s system 74% cpu 0.469 total
zplg だとmodule 毎に読み込み時間を出せる, autopairは機能の割に読み込みが遅い気もする.
❯ zplg times Plugin loading times: 0.043 sec - sindresorhus/pure 0.007 sec - sorin-ionescu/prezto 0.020 sec - zsh-users/zsh-history-substring-search 0.002 sec - junegunn/fzf-bin (command) 0.050 sec - zsh-users/zsh-autosuggestions 0.003 sec - zsh-users/zsh-completions 0.035 sec - zdharma/fast-syntax-highlighting 0.017 sec - b4b4r07/enhancd 0.003 sec - desyncr/auto-ls 0.042 sec - hlissner/zsh-autopair 0.009 sec - zdharma/zui 0.003 sec - zdharma/zplugin-crasis 0.003 sec - zdharma/history-search-multi-word 0.002 sec - zdharma/zsh-diff-so-fancy (command) Total: 0.239 sec
踏んだbug
zplugin を入れた直後 exit code が0以外だと繰り返しexit code が表示されるbug が発生した.
以下は ctrl+c でsigint を送信した場合

debug でやったこと
- zplugin を含む最小の構成でzshrc を記述 -> bug発生
- singal 周りの記述を確認, 本家zshからコードを移植していたようなので, 本家とのdiffを確認
- zshrcの他の設定に問題ないか binary chopでsearch
-
setopt print_exit_valueが原因だった ため設定を削除
-
- 結論コレと同様だった https://github.com/zdharma/zplugin/issues/45
TODO memo
Redash meetup #5 参加レポート
TL;DR;
4/23 にRetty で行われた Redash Meetup にお邪魔してきたので, 参加レポートもどきの手元のメモ公開させていただきます。。
イベントURL
Redashとは
Redash とは Python製の の OSS/SaaS のBIツール (Tableau, Looker などの仲間) いろいろなデータソース(BQ, Athena, MySQL, SpreadSheet)に対して, ユーザライクなinterfaceを提供して可視化などを行うツールです。
自分も普段の業務で仮説検証のための集計やABテストのための集計などで日頃からお世話になっています。
以下, 登壇内容についてです。
OP talk
参加者へのアナウンスで拍手のお願いがあったのが斬新でした 笑 良さそうなので主催側の勉強会でも取り入れたいです。
改めて振り返る Redashの使いどころ (ユニトーン 有田)
- 有田さんはOSS版のRedash のメンテナの一人
- 会場内でver7.0 使っている人3割くらい
- バージョンアップの歴史, 国内で話題になったイベントの歴史などの振り返り
Redash の良さの振り返り
- OSSかつwebベース
- ユーザーフレンドリ
- クエリをURLで共有できる
- 様々なデータベースの集計クエリが集約される
- クエリが集約されるので, 秘伝のクエリが生まれにくい
- hackable
クエリランナー については存在を全然知らなかったです。
登壇者の有田さんがブログを書いているようなので, あとで読ませていただこうと思います。
Retty における Redash の活用事例 (Retty 田中 さん)
www.slideshare.net
Retty さんの取り組みに関する過去の技術ブログ記事はこちら
- データ量が増加, ステークホルダの増加, 意思決定難易度の上昇から, 瞬時に多様な観点からの分析が必要なフェーズになってきた
- Redash, DataPotal, SpreadSheet などを組み合わせて分析を行っている, それぞれの用途は以下の通り
Data Potal
- DataPotal ではチャネル遷移の分析の可視化
- dailyで更新させているので, ad-hoc にクエリ打たなくても気になった時に結果を見に行ける
Spread Sheet
- 細かな数値間の確認
Redash
時系列情報の可視化は実感としてもRedashの方がやりやすいなと思います
Redash 利用の課題感
- 数値を見る習慣をどうやって作る?
- ツールの使い分け
- Scheduled Query の増加に伴う実行コスト増加(Retty だとBQ利用のため辛かったよう)
- こちらtweetしたところリプでスキャン件数事前に見れると教えていただけました :pray:
データソースがBQの場合はスキャンされる行数や件数が都度redash実行時に確認する事ができます。ただ、自分以外に公開する時は注意が必要ですね。 https://t.co/tfqGnjUI7h
— 塚田 純人@レアジョブ(engineer) (@19840209) 2019年4月23日
[MEMO] A/Bテストの効果測定はスプレッドシートなどで行っている, SpreadSheet, DataPotal で済むならそちらを使ったほうが効率的
[MEMO] 現状Rettyでは意思決定でのデータ活用がメインなので今後はデータを利用した機能の開発をやっていきたいそう
Redash で何を見るのか?(エブリー 島田 さん)
普段は DWH アーキテクト としてお仕事されているそう。
インフラ構成
- インフラ構成とクエリ数紹介など
- Spark で以下のようにETL
- DataRake S3-> DWH TD ->DataMart Redash
上記のDataRake, DWH, Data Mart の概念の話は yuzutas0さんの記事がとてもわかりやすかったです。
- ユーザはPO, アナリスト, 機械学習エンジニア, マーケターなど
何を見るのか
実際に見ているKPI紹介
DAU, 継続率(cohort chart) からKPI treeの各構成要素の見方の紹介
例えば継続率は以下のように分解される
- 継続率
- 認知
- プレファレンス
- 配荷率
課題感
- データガバナンス
- SQLクエリの管理と権限設定
- 管理という観点から言えば特にBQ使うのであれば, エンジニア的にはレビューしたい <- わかる
- 協力会社へのデータ提供が難しい (Looker使ってみたが...)
LT1 チームの BI や可視化強化に Redash はどうかと雑談した時の話 (はてな koudenpa さん)
www.slideshare.net
BQをRedash に持ってくるのではなくて, BQの方にサービスログをembulkで持っていくのを検討中らしい。
Embulk 辛そうな話が DPCT で伺った話だと多かったが未経験なので感覚がわからないです。。。
LT2 Ruby エンジニア選ぶ Redash の好きなところ Top10 (フリーランス samemuraさん)
特に共感したのはこの辺り
- 逆にGUI凝っていないからSQL書いて可視化までが早い
- 他のクエリの結果を使って負荷の軽減と再利用ができる, クエリの結果がキャッシュできる
- 管理画面が不要になる, 簡単な分析依頼ならRedash 内で完結する
感想
ユーザ側とデータエンジニア側の方両方いらっしゃったみたいでいろいろなお話が伺えて楽しかったです。 欲を言えばもう少し深い話が聞きたかったので, 懇親会があると嬉しかったかもです 笑
Redash のメジャーバージョンに追いつくまでは開催していただける ということなので, 次回も楽しみにしています!
クエリ管理の話 とか オンプレ非DockerのRedashのバージョン上げる話 とか機会あればLTなどで話したいなと思いました。
新卒(ML)エンジニアにオススメの書籍・Web サイト等
新卒だった頃の自分に薦めたい本の一覧とそれらに対してのコメントを書いていきます。 自分が新卒だったのは2年前なので最近だともっと良い本があるかもしれません。
まとめていった結果MLに限らず一般的な新卒webエンジニアに薦めたい本になりました。
ちなみに 自分がここ数年で読んだ本一覧はこちらにまとめています。https://booklog.jp/users/schumi543
想定読者
自分と同様, 大学の研究で簡単な数値計算や機械学習のコードは書いたことがあるが, 大きめのソフトウェアを書いたことがない新卒MLエンジニア。
ソフトウェア基礎
Linux, shell
IDE (Matlab, Rstudio, Pycharm)) などに慣れていてまともに Linux触ったことなかったので最初厳しかった気がします。 以下の2冊は自分で実際にCやgo で低レイヤのAPI触りながら仕組みが理解できるのでオススメです。
![[試して理解]Linuxのしくみ ~実験と図解で学ぶOSとハードウェアの基礎知識](https://images-fe.ssl-images-amazon.com/images/I/51r%2BeNsY2fL._SL160_.jpg "[試して理解]Linuxのしくみ ~実験と図解で学ぶOSとハードウェアの基礎知識")
[試して理解]Linuxのしくみ ~実験と図解で学ぶOSとハードウェアの基礎知識
- 作者: 武内覚
- 出版社/メーカー: 技術評論社
- 発売日: 2018/02/23
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (1件) を見る

- 作者: 渋川よしき,ごっちん
- 出版社/メーカー: ラムダノート
- 発売日: 2017/10/23
- メディア: 単行本(ソフトカバー)
- この商品を含むブログを見る
スクリプトを書くのはad-hocになりがちですが, 別のコマンド, APIを知っていると より効率的に書ける ということは割とよくあります(shell以外も)。 一度リファレンスをざっと通読しておくとよいかなと思います。
![[改訂第3版]シェルスクリプト基本リファレンス ──#!/bin/shで、ここまでできる (WEB+DB PRESS plus)](https://images-fe.ssl-images-amazon.com/images/I/41i956UyusL._SL160_.jpg "[改訂第3版]シェルスクリプト基本リファレンス ──#!/bin/shで、ここまでできる (WEB+DB PRESS plus)")
[改訂第3版]シェルスクリプト基本リファレンス ──#!/bin/shで、ここまでできる (WEB+DB PRESS plus)
- 作者: 山森丈範
- 出版社/メーカー: 技術評論社
- 発売日: 2017/01/20
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (1件) を見る
git
学生の時はバージョン管理システムをまともに使ってなかったので, 慣れるのに苦労しました。。。 概念に慣れるまでが一番厳しかったのですがとっつきやすかったのは以下の本でした。 マンガだと逆に抵抗感ある方もいるかも知れませんが, 内容と説明両方の面から今見ても十分オススメできる本です

- 作者: 湊川あい,DQNEO
- 出版社/メーカー: シーアンドアール研究所
- 発売日: 2017/04/21
- メディア: Kindle版
- この商品を含むブログを見る
正規表現
コードやログを読むときに普通に検索するより正規表現の知識があると効率がとても良くなります。
")
正規表現辞典 改訂新版 (DESKTOP REFERENCE)
- 作者: 佐藤竜一
- 出版社/メーカー: 翔泳社
- 発売日: 2018/05/24
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (1件) を見る
データ構造とアルゴリズム
情報系あるいはそれに近い分野が専門だった場合, 大学で理屈は学んでいるかと思いますが, 実際にコードに落とすには慣れが必要なので オンラインジャッジ系の競技プログラミングの問題を解いてみるのはオススメです。
今だと AtCoderがとっつきやすくて良いかなと思います。
以下の入門記事から初めてステップアップしていくのが良さそうです。
集団開発の基礎
テスト, コードの書き方, 開発手法というトピックで何冊か選びました。
個人的にはここが会社で開発するうえで一番知識のギャップがあったなと感じます。 実際に仕事やってレビューしてもらう過程で知識は身についていくかと思いますが, 並行してこの辺りの書籍で勉強しておくとよさそうです。
テスト

- 作者: Kent Beck,和田卓人
- 出版社/メーカー: オーム社
- 発売日: 2017/10/14
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (1件) を見る
")
JUnit実践入門 ~体系的に学ぶユニットテストの技法 (WEB+DB PRESS plus)
- 作者: 渡辺修司
- 出版社/メーカー: 技術評論社
- 発売日: 2012/11/21
- メディア: 単行本(ソフトカバー)
- 購入: 14人 クリック: 273回
- この商品を含むブログ (69件) を見る
コードの書き方
")
リーダブルコード ―より良いコードを書くためのシンプルで実践的なテクニック (Theory in practice)
- 作者: Dustin Boswell,Trevor Foucher,須藤功平,角征典
- 出版社/メーカー: オライリージャパン
- 発売日: 2012/06/23
- メディア: 単行本(ソフトカバー)
- 購入: 68人 クリック: 1,802回
- この商品を含むブログ (140件) を見る
")
新装版 リファクタリング―既存のコードを安全に改善する― (OBJECT TECHNOLOGY SERIES)
- 作者: Martin Fowler,児玉公信,友野晶夫,平澤章,梅澤真史
- 出版社/メーカー: オーム社
- 発売日: 2014/07/26
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (11件) を見る
開発手法
見積もりとコミュニケーションのための本です。
手を動かす側の職だったとしても, プロジェクト or プロダクトマネージャがどう考えているか知ることは有用だと思います。

- 作者: Jonathan Rasmusson,西村直人,角谷信太郎,近藤修平,角掛拓未
- 出版社/メーカー: オーム社
- 発売日: 2011/07/16
- メディア: 単行本(ソフトカバー)
- 購入: 42人 クリック: 1,991回
- この商品を含むブログ (257件) を見る
設計
小規模なコードだといきなり書き始めてもなんとかなりますが, ある程度以上のコードは設計せずに書き出すと論理の不整合などで厳しくなってきます。 運良く完成できたとしても, 保守性が厳しいコードになりがちなので設計は少し勉強しておいたほうが良いでしょう。
設計の経験がない場合 コード書き始める前に設計や方針を先輩方にレビューしてもらうと良いと思います。

- 作者: 児玉公信
- 出版社/メーカー: 日経BP社
- 発売日: 2011/05/26
- メディア: 単行本
- 購入: 6人 クリック: 23回
- この商品を含むブログ (6件) を見る

現場で役立つシステム設計の原則 ~変更を楽で安全にするオブジェクト指向の実践技法
- 作者: 増田亨
- 出版社/メーカー: 技術評論社
- 発売日: 2017/07/05
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (1件) を見る
また、オブジェクト指向のSOLID原則の解説について学ぶには, 最近技術書典で出されていた以下の本がオススメです。 (自分が今まで見た中で一番わかり易いと感じました)
web開発基礎
開発するソフトの全体像掴むためにもwebの基礎技術については勉強しておいたほうが良いかと思います。
")
Webを支える技術 -HTTP、URI、HTML、そしてREST (WEB+DB PRESS plus)
- 作者: 山本陽平
- 出版社/メーカー: 技術評論社
- 発売日: 2010/04/08
- メディア: 単行本(ソフトカバー)
- 購入: 143人 クリック: 4,320回
- この商品を含むブログ (183件) を見る
ドメイン知識
自分の場合はアドテクなので以下をオススメします。web業界は特に変遷激しいので各々の会社の先輩に聞くのが良いかと思います。

- 作者: 広瀬信輔
- 出版社/メーカー: 翔泳社
- 発売日: 2016/03/11
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (4件) を見る
上記はどちらかと言うとビジネス職の人向けの話が多いので, 個人的にはこちらのほうがわかりやすかったです。 booth.pm
SQL
データベースの利用者としてみるか, 設計者としてみるかでオススメの本変わってきますが, 利用者の場合以下2冊がおすすめです。
")
10年戦えるデータ分析入門 SQLを武器にデータ活用時代を生き抜く (Informatics &IDEA)
- 作者: 青木峰郎
- 出版社/メーカー: SBクリエイティブ
- 発売日: 2015/06/30
- メディア: 単行本
- この商品を含むブログ (7件) を見る

- 作者: 加嵜長門,田宮直人,丸山弘詩
- 出版社/メーカー: マイナビ出版
- 発売日: 2017/03/27
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (1件) を見る
エンジニアとしての心構え的なもの
エンジニアの哲学, 仕事の作法や向き合い方, キャリアなどの話題に触れているもので今も度々読み返している書籍たちです。

プリンシプル オブ プログラミング3年目までに身につけたい一生役立つ101の原理原則
- 作者: 上田勲
- 出版社/メーカー: 秀和システム
- 発売日: 2016/03/23
- メディア: 単行本
- この商品を含むブログ (11件) を見る

- 作者: ジョン・ソンメズ
- 出版社/メーカー: 日経BP社
- 発売日: 2016/06/02
- メディア: Kindle版
- この商品を含むブログ (8件) を見る

ベタープログラマ ―優れたプログラマになるための38の考え方とテクニック
- 作者: Pete Goodliffe,柴田芳樹
- 出版社/メーカー: オライリージャパン
- 発売日: 2017/12/15
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (4件) を見る